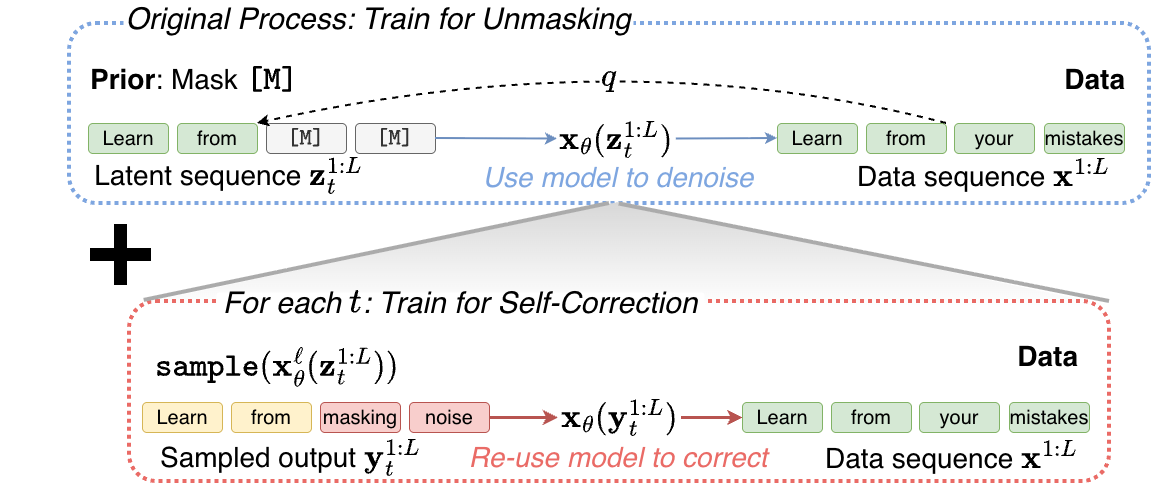
We evaluate ProSeCo across multiple tasks, ranging from complex reasoning in code and
math to molecular design and unconditional text generation.
Across the board, we find that the ability to self-correct allows our models to generate better samples
faster.
LLaDA SFT: Math & Code Benchmarks
Task & Dataset: We begin by applying supervised fine-tuning (SFT) to the 8B-parameter
LLaDA-Base model, aiming to improve its reasoning capabilities.
We train for ~40 billion tokens on a blend of the rStar-Coder (code) and
OpenMathInstruct-2 (math) datasets.
Baselines: We compare our ProSeCo SFT against the vanilla SFT of LLaDA-Base, off-the-shelf
LLaDA variants (Base, Instruct, 1.5), an autoregressive equivalent (Llama 3.1 8B Instruct), and alternative
MDM corrector mechanisms like ReMDM and PRISM.
Takeaway: ProSeCo significantly outperforms all diffusion baselines and beats the comparable
Llama 3.1 AR model on three out of four benchmarks.
Furthermore, as shown in the figures below, ProSeCo delivers vastly superior quality-efficiency trade-offs.
It can generate samples 2–3x faster than baseline MDMs without losing accuracy (Fast regime), or leverage
increased inference-time compute to scale performance well beyond standard limitations (Max regime).
| Model |
Corrector
Sampling |
Code |
Math |
HumanEval
(0-shot) |
MBPP
(3-shot) |
GSM8K
(5-shot) |
Minerva
(4-shot) |
| Off-the-Shelf 8B Models |
| Llama3.1-Instruct |
✗ |
58.54 |
57.80 |
76.88 |
31.10 |
| LLaDA 1.5 |
✗ |
43.90 |
27.20 |
81.12 |
35.10 |
| LLaDA-Instruct |
✗ |
40.24 |
29.40 |
78.85 |
33.32 |
| + ReMDM |
✓ |
40.24 |
35.20 |
79.08 |
32.72 |
| + PRISM |
✓ |
42.70 |
32.30 |
-- |
-- |
| LLaDA-Base |
✗ |
33.54 |
40.40 |
66.72 |
27.88 |
| Our SFT with LLaDA-Base 8B Model |
| Vanilla SFT |
✗ |
48.17 |
43.20 |
77.48 |
29.74 |
| + ReMDM |
✓ |
43.90 |
42.40 |
80.97 |
29.90 |
| ProSeCo SFT (Ours) |
✗ |
52.44 |
44.00 |
79.45 |
32.42 |
| + ProSeCo Sampling |
✓ |
62.20 |
50.20 |
82.18 |
35.10 |
Table 1: Pass@1 accuracy on
Code and Math benchmarks.
Best values per column in bold, second best underlined.
Analyzing the quality-efficiency trade-off for ProSeCo.
Standard MDMs (Baseline; gray dot) attain best performance when decoding a
single token in every step.
ProSeCo models can vary number of corrector steps and attain comparable performance more efficiently with
fewer unmasking steps (Ours: Fast; green star), achieve even better quality
for modest increase in compute budget (Ours: Balanced; orange star), or
maximize quality by scaling inference-time compute even further (Ours: Max; blue
star)
Pareto frontier of parallel decoding and quality.
When decoding in parallel (i.e., fewer unmasking steps on \(x\)-axis), quality deteriorates.
Applying a modest number of corrector steps, allows ProSeCo models to recover from these errors and extend
this frontier.
Guidance Results: Molecule Property
Maximization
Task & Dataset: We test guided generation using the QM9 dataset, consisting
of SMILES string representations of molecules.
The goal is to maximize specific chemical properties, namely, ring count and drug-likeness
(QED), without causing the generated samples to collapse into invalid or highly repetitive sequences.
Baselines: Autoregressive (AR), standard masked diffusion (MDLM), uniform categorical noise
diffusion (UDLM), and ReMDM.
Takeaway: A classic problem with classifier-free guidance (CFG) is that pushing guidance
strengths too high degrades sample diversity and quality.
ProSeCo naturally recovers from these guidance-induced errors, noticeably pushing the Pareto frontier up and
to the right.
It generates higher quantities of novel, valid molecules while simultaneously hitting higher property scores.
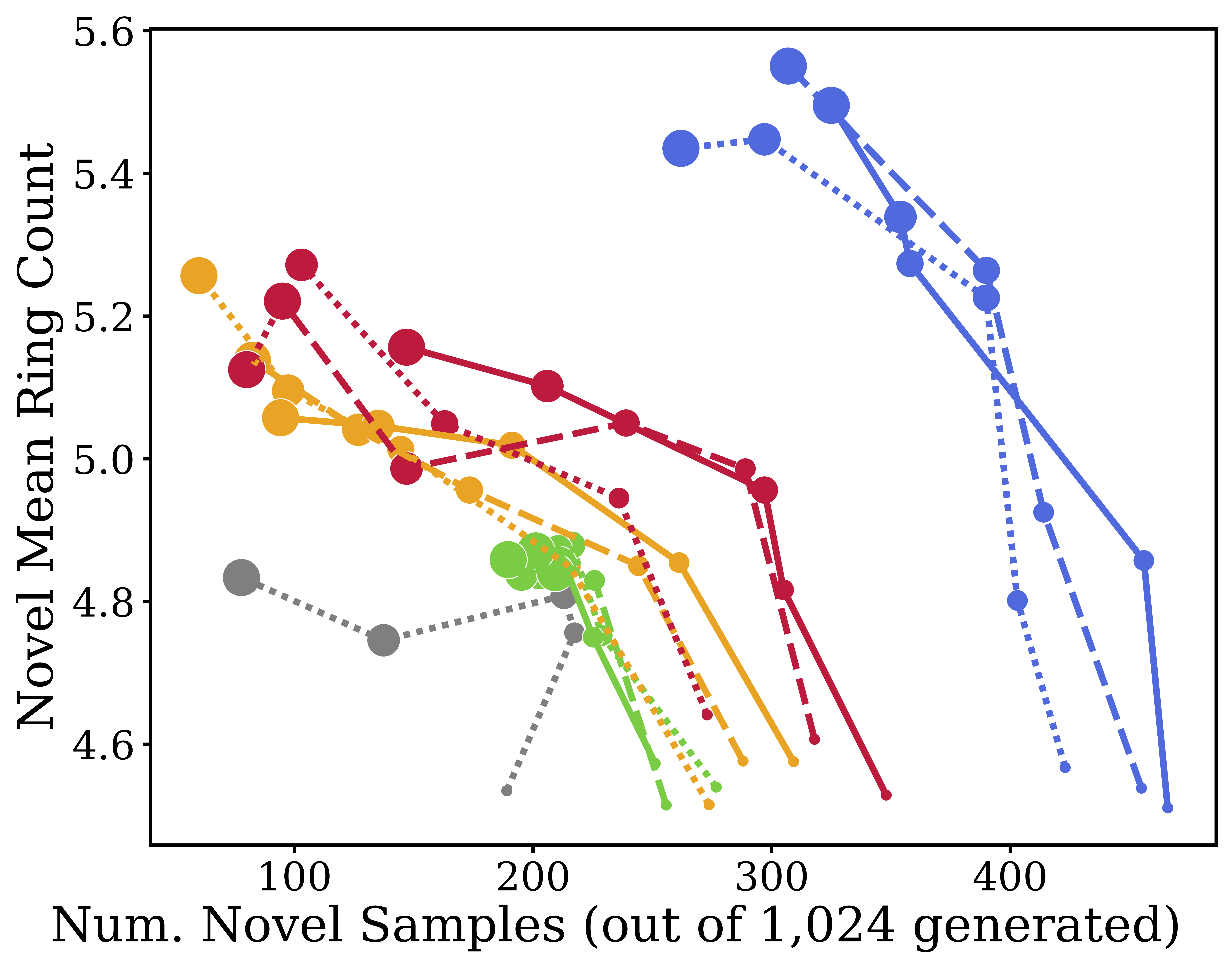
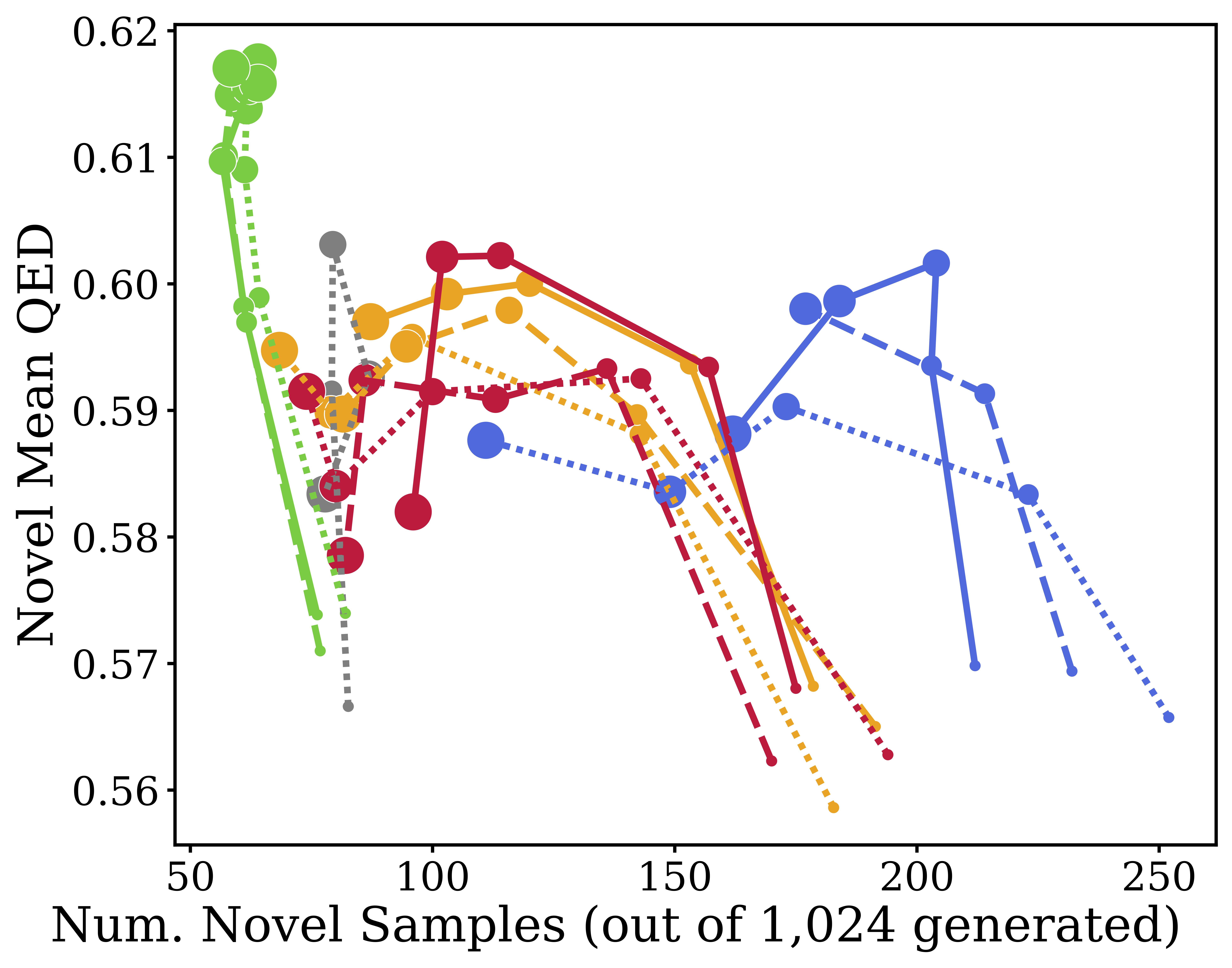
ProSeCo better navigates the novelty-property maximization Pareto frontier.
Values correspond to number of novel samples (valid and unique molecules not present in the QM9 dataset;
\(x\)-axis) and mean property value of novel samples (\(y\)-axis) for controlled generation using discrete
classifier-free guidance, with varying unmasking steps \(T\) (line style) and guidance strength \(\gamma\)
(marker size).
(Left) Maximizing the ring count property.
(Right) Maximizing the drug likeness (QED) property.
Unconditional Text Generation
Task & Dataset: Finally, we evaluate open-ended, unconditional text generation by training
models from scratch on the OpenWebText dataset to generate 1,024-token sequences.
Baselines: AR, standard MDLM, ReMDM, and PRISM.
Takeaway: ProSeCo generates fluent text with high sample quality (measured by MAUVE and
Generative Perplexity) without collapsing the diversity of the generated outputs (measured by Entropy).
Crucially, it does this much more efficiently than alternatives: a ProSeCo model using just 256 inference
steps achieves comparable quality to PRISM at 512 steps and ReMDM at 1024 steps.
| Model |
MAUVE (↑) |
Gen.
PPL (↓) |
Entropy (↑) |
| 128 |
256 |
512 |
1024 |
128 |
256 |
512 |
1024 |
128 |
256 |
512 |
1024 |
| Data |
1.00 |
14.8 |
5.44 |
| AR (T=1024) |
0.760 |
12.1 |
5.22 |
| MDLM |
0.015 |
0.023 |
0.031 |
0.042 |
61.5 |
55.8 |
53.0 |
51.3 |
5.52 |
5.49 |
5.48 |
5.46 |
| ReMDM |
0.057 |
0.216 |
0.350 |
0.403 |
42.5 |
30.5 |
21.1 |
28.6 |
5.43 |
5.34 |
5.21 |
5.38 |
| PRISM |
0.118 |
0.294 |
0.423 |
0.527 |
21.5 |
18.0 |
16.4 |
15.3 |
5.18 |
5.15 |
5.12 |
5.10 |
| ProSeCo (Ours) |
0.295 |
0.557 |
0.597 |
0.604 |
23.1 |
16.5 |
13.2 |
10.9 |
5.45 |
5.39 |
5.29 |
5.22 |
Table 2: Unconditional
generation sample quality for models trained on OpenWebText across various inference budgets.
 2
Nvidia
2
Nvidia